Exploring Hierarchical Graph Representation for Large-Scale Zero-Shot Image Classification
ECCV 2022
- Kai Yi
- Xiaoqian Shen
- Yunhao Gou
- Mohamed Elhoseiny King Abdullah University of Science and Technology (KAUST), Saudi Arabia
Abstract
The main question we address in this paper is how to scale up visual recognition of unseen classes, also known as zero-shot learning, to tens of thousands of categories as in the ImageNet-21K benchmark. At this scale, especially with many fine-grained categories included in ImageNet-21K, it is critical to learn quality visual semantic representations that are discriminative enough to recognize unseen classes and distinguish them from seen ones. We propose a Hierarchical Graphical knowledge Representation framework for the confidence-based classification method, dubbed as HGR-Net. Our experimental results demonstrate that HGR-Net can grasp class inheritance relations by utilizing hierarchical conceptual knowledge. Our method significantly outperformed all existing techniques, boosting the performance 7% compared to the runner-up approach on the ImageNet-21K benchmark. We show that HGR-Net is learning-efficient in few-shot scenarios. We also analyzed our method on smaller datasets like ImageNet-21K-P, 2-hops and 3-hops, demonstrating its generalization ability. Our benchmark and code will be made publicly available.
Intuition
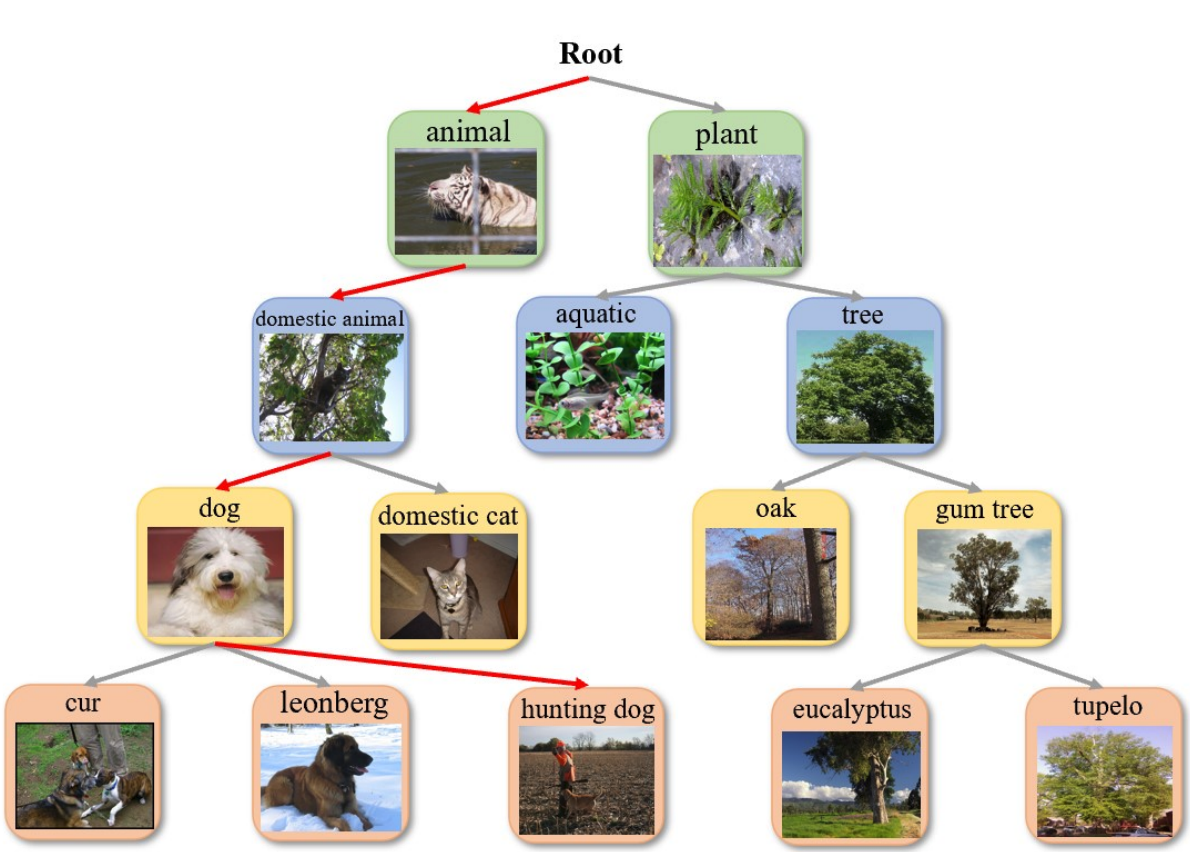
Method: HGR-Net
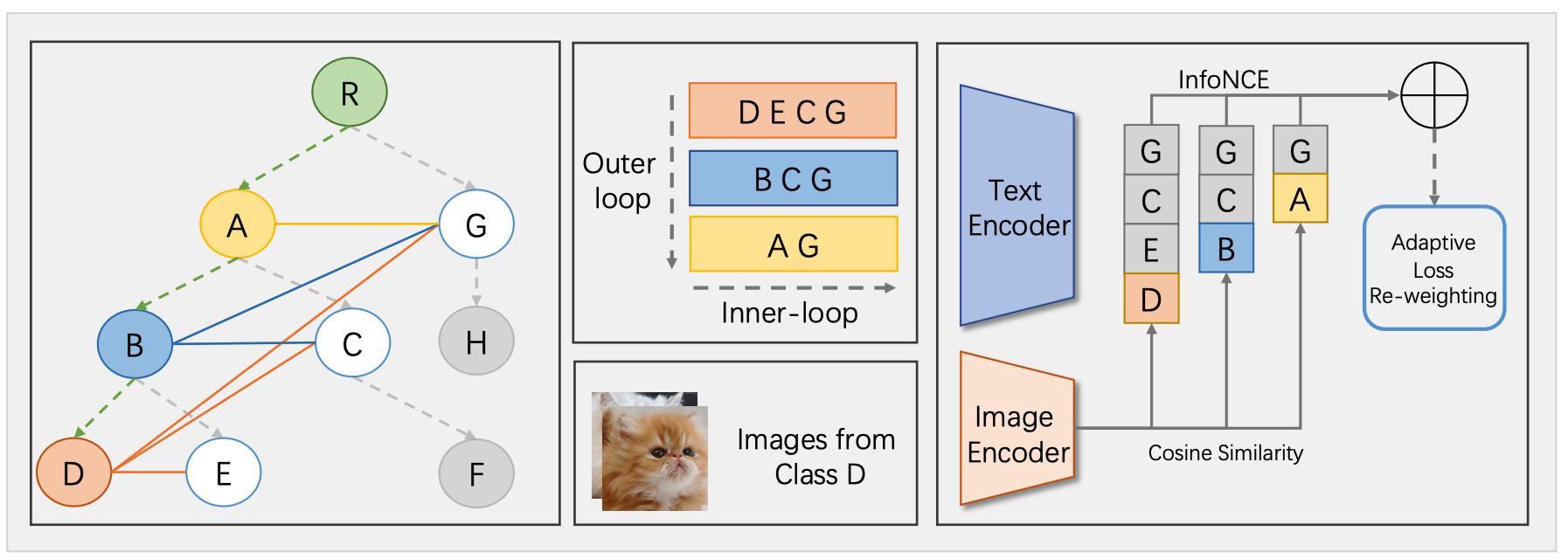
Algorithm

Results on ImageNet-21K-D
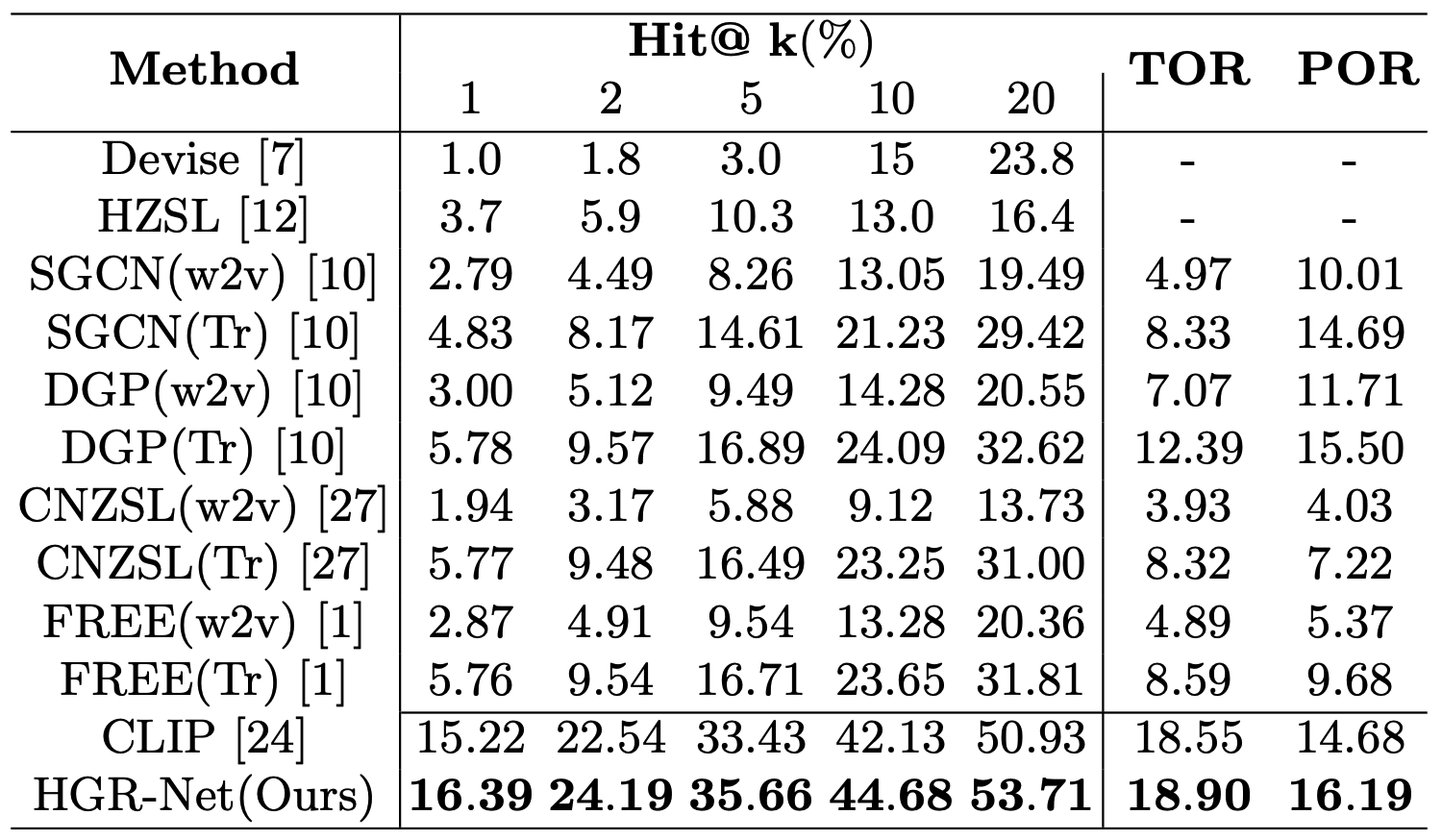
More results could refer to the original paper.
Citation
If you find our work useful in your research, please consider citing:
@article{yi2022exploring,
title={Exploring hierarchical graph representation for large-scale zero-shot image classification},
author={Yi, Kai and Shen, Xiaoqian and Gou, Yunhao and Elhoseiny, Mohamed},
journal={ECCV},
year={2022}
}